Java Agent 开发使用的那些坑
Java Agent 是一个特殊的 Jar 包,其编写和普通的 Java 应用区别不大。一般情况下,我们使用 Java Agent 都是为了使用 Java instrument 机制,因为其一般情况下只能在 Java Agent 中调用。(有些暴力内存搜索的黑客手段也可以,暂且忽略,详见 Java内存攻击技术漫谈 )。
Java instrument 机制是一种对 Java 类和字节码进行后期处理的机制,其主要功能包括:
getAllLoadedClasses()获取当前进程加载的所有的类addTransformer(ClassFileTransformer transformer, boolean canRetransform)注册一个 transformer
transformer 需要实现 transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) 。在类加载或者 retransform 的过程中,transformer 类似一个 hook,可以收到原始的类字节码,然后按需修改后返回,如果不需要修改,返回 null 即可。
基于 Java instrument 机制动态修改字节码可以很方便的去做一些监控和安全类的功能,也经常被黑客所利用,比如:
- 不修改业务的情况下,记录关键函数的调用的时间、次数、链路等
- 不重新上线的情况下,热修复程序的 bug
- Rasp 安全产品,在敏感位置插入检测逻辑,实现安全检测和防御
- 插入自定义的恶意代码实现内存马,不需修改磁盘文件,更加隐蔽
在主机安全产品上,我们使用这些技术来实现内存马扫描相关的功能,首先使用 getAllLoadedClasses 和一些反射的手段获取到一些类,后续通过 transform 监控类的加载。
如果初筛结果是可疑的,我们就将其上传到服务端去做进一步的检测。
内存马检测 Agent 和 Rasp 产品最大的区别是是否修改字节码,Rasp 要使用这个机制去修改字节码来做检测和防御,而内存马检测 Agent 能将其字节码保存下来即可,也就是 transform 函数一定返回 null。
transform 函数具体的函数定义和参数说明如下:
1/**
2 * Transforms the given class file and returns a new replacement class file.
3 * This method is invoked when the {@link Module Module} bearing {@link
4 * ClassFileTransformer#transform(Module,ClassLoader,String,Class,ProtectionDomain,byte[])
5 * transform} is not overridden.
6 *
7 * @implSpec The default implementation returns null.
8 *
9 * @param loader the defining loader of the class to be transformed,
10 * may be {@code null} if the bootstrap loader
11 * @param className the name of the class in the internal form of fully
12 * qualified class and interface names as defined in
13 * <i>The Java Virtual Machine Specification</i>.
14 * For example, <code>"java/util/List"</code>.
15 * @param classBeingRedefined if this is triggered by a redefine or retransform,
16 * the class being redefined or retransformed;
17 * if this is a class load, {@code null}
18 * @param protectionDomain the protection domain of the class being defined or redefined
19 * @param classfileBuffer the input byte buffer in class file format - must not be modified
20 *
21 * @throws IllegalClassFormatException
22 * if the input does not represent a well-formed class file
23 * @return a well-formed class file buffer (the result of the transform),
24 * or {@code null} if no transform is performed
25 *
26 */
27
28byte[] transform(ClassLoader loader,
29 String className,
30 Class<?> classBeingRedefined,
31 ProtectionDomain protectionDomain,
32 byte[] classfileBuffer)
33 throws IllegalClassFormatException
- className:虽然文档上没有提到,但是此参数可能为 null,判断下即可。如果确实需要 name,可以使用 asm 等框架去解析字节码得到。
- classBeingRedefined:这个也需要区分是不是 null,不难理解。如果这个类是正在加载,transform 完成才能继续后续的操作,也就是说这个时候还没有加载完,肯定是没有对应的 Class 对象的。如果这个类已经加载了,是被 redefine / retranform 的,那就可以得到原始的对应的 Class 对象。
- classfileBuffer:类的字节码,这个地方有个重要的问题是这个字节码是哪个阶段的,这个官方文档说的也比较清楚了
ClassLoader.defineClass加载的类是获取的是其参数,也就是原始字节码Instrumentation.redefineClasses加载的类是获取的是其名为definitions参数的getDefinitionClassFile()的结果,可以先简单理解为修改后的字节码。
很多文章中提到 redefineClasses 重定义后的类,无法在 retransformClass 方法后获取到? 如:
宽字节的 基于javaAgent内存马检测查杀指南 中提到的:
在这里有一个大坑,也就是在调用
retransformClass方法的时候参数中的字节码并不是调用redefineClass后被修改的类的字节码。对于冰蝎来讲,我们根本无法获取被冰鞋修改后类的字节码,这一点才是冰蝎最骚的地方。
或是 https://xz.aliyun.com/t/11003#toc-14 中:
被redefineClasses方法重载过的类,其重载后的类的字节码无法在下一次调用redefineClasses或retransformClasses中获取到,所以我们就没办法获取到其字节码并做过滤以及检测
暂时不确定为什么会有这个说法,但是经过我们的测试并未发现该问题。
在 Java Agent 的开发和使用过程中,我们踩了一些坑,这里逐个的分享一下
Attach Agent 过程中
Java Agent 支持在进程启动的时候使用类似 java -javaagent:/path/to/agent.jar 的参数加载,也可以在运行时使用 Java Attach 技术动态加载。在牧云产品上,为了减少对业务的侵入性,都是使用的动态加载,其大概流程如下:
- 探针创建创建一个
.attach_pid<pid>文件 - 向需要被 attach 的 Java 进程发送一个 QUIT 信号
- Java 进程收到 QUIT 信号后,检测相关路径下的
.attach_pid<pid>文件,若存在则创建 socket 文件:.java_pid<pid>。 - 探针借助
.java_pid<pid>socket 文件与 Java 进程进行通信,如load library命令使目标进程加载指定的 agent.jar。
其中 <pid> 变量为 Java 进程的 pid。
attach_pid 等文件路径和权限的问题
上面提到了两个重要的文件,.attach_pid<pid> 和.java_pid<pid>,这两个文件在绝大多数的场景下路径都是固定的,/tmp 和 cwd 下面,但是总有个别的版本是奇奇怪怪的路径,比如
- 不是使用的
/tmp硬编码路径,而是受到java.io.tmpdir影响。这个在命令行中配置了还好,要是在代码中配置了,外界也无从得知真正的 tmpdir 在哪里,从而导致找不到对应的文件。https://bugs.openjdk.org/browse/JDK-7009828 - 某些版本 Attach 端会使用
/proc/$pid/root/tmp这样的路径来支持容器外 attach 容器内的进程,但是如果 attach 进程也在容器内,那访问这个路径会 Permission Denied。https://github.com/openjdk/jdk/commit/737c0cd7a53bd1e0d8315bdd9f32c4e1991197ce - systemd 存在一些安全配置,如果 Java 进程是其接管的,那 Java 的
/tmp可能会被重新挂在到类似/tmp/systemd-xxx/tmp这样的路径下面。https://github.com/alibaba/arthas/issues/1783
attach 的时候,Java 还会校验对端 attach 的进程的 uid,如果不一致就拒绝,这个机制在 Java 新老版本中也略有差异。老版本中需要 uid 严格一致,而新版本中,相同 uid 或者 root 用户都可以。选择哪个用户去 attach 与上述路径的问题也有一定的关系,至于原因,可以自己思考下。
这些问题当然也不难解决,就是需要细心的去测试和适配。
如何获取 ns_pid
.attach_pid<pid> 和.java_pid<pid> 两个文件中的 pid 是 Java 进程自己 getpid 获取的,如果 Java 进程在容器内,那和容器外观察到的 pid 是不一致的,应该使用 ns_pid 才行,在 /prc/$pid/status 中。
NSpid Thread ID in each of the PID namespaces of which pid is a member. The fields are ordered as for NStgid. (Since Linux 4.1.)
但是在 Linux 4.1 之前怎么办呢?有些好心人给了解决方案,也就是先在容器外找到所有的 Java 进程,比如其 pid 为 1234,然后遍历相关的 sched 文件 /proc/1234/root/proc/[nspid]/sched ,如果这个文件第一行是类似 java (1234, #threads: ) 的字样,就可以得到其 nspid 了。
不过要注意的是,此方法只能在老版本中使用,v4.14-rc1 及以后版本 sched 文件第一行的 pid 改成了容器内 pid,不再是 host pid。
参考 https://github.com/jattach/jattach/blob/c96c491e293ad767d4dccd9d90a730f871f46b04/src/posix/psutil.c#L70 和 https://github.com/torvalds/linux/commit/74dc3384fc7983b78cc46ebb1824968a3db85eb1 。
Attach Agent 触发 Full GC,导致服务质量受损
某客户反馈,在 Java 内存马扫描期间 Java 进程会发生 Full GC 导致大概半秒钟到两秒钟的 stw,并提供了相关的日志:
12022-02-23T02:16:59.339+0800: 18921.358: [Full GC (Heap Inspection Initiated GC) 2022-02-23T02:16:59.339+0800: 18921.358: [CMS: 129172K->123008K(2097152K), 1.1170918 secs] 2514045K->123008K(5872064K), [Metaspace: 123531K->123531K(1165312K)], 1.1187527 secs] [Times: user=1.06 sys=0.02, real=1.12 secs]
2Heap after GC invocations=118 (full 1):
3 par new generation total 3774912K, used 0K [0x0000000640000000, 0x0000000740000000, 0x0000000740000000)
4 eden space 3355520K, 0% used [0x0000000640000000, 0x0000000640000000, 0x000000070cce0000)
5 from space 419392K, 0% used [0x0000000726670000, 0x0000000726670000, 0x0000000740000000)
6 to space 419392K, 0% used [0x000000070cce0000, 0x000000070cce0000, 0x0000000726670000)
7 concurrent mark-sweep generation total 2097152K, used 123008K [0x0000000740000000, 0x00000007c0000000, 0x00000007c0000000)
8 Metaspace used 122419K, capacity 128918K, committed 131072K, reserved 1165312K
9 class space used 13739K, capacity 14961K, committed 15360K, reserved 1048576K
10}
11
12 num #instances #bytes class name
13----------------------------------------------
14 1: 193690 30840048 [C
15 2: 15573 14899208 [B
16 3: 84707 7454216 java.lang.reflect.Method
17 4: 197501 6320032 java.util.concurrent.ConcurrentHashMap$Node
18 .......
在这里可以看到 Full GC 的原因是 Heap Inspection Initiated GC,这是堆检查导致的,正常内存回收类的 GC 不是这样的。
通过查阅源码,我们得知 Heap Inspection 原来也是通过操作系统的信号来实现的,结合源码,就很容易明白原因了:
1switch (sig) {
2 case SIGBREAK: {
3 // Check if the signal is a trigger to start the Attach Listener - in that
4 // case don't print stack traces.
5 if (!DisableAttachMechanism && AttachListener::is_init_trigger()) {
6 continue;
7 }
8 // Print stack traces
9 // Any SIGBREAK operations added here should make sure to flush
10 // the output stream (e.g. tty->flush()) after output. See 4803766.
11 // Each module also prints an extra carriage return after its output.
12
13 ......
14
15 if (PrintClassHistogram) {
16 VM_GC_HeapInspection op1(gclog_or_tty, true /* force full GC before heap inspection */);
17 VMThread::execute(&op1);
18 }
19 if (JvmtiExport::should_post_data_dump()) {
20 JvmtiExport::post_data_dump();
21 }
22 break;
23 }
1bool AttachListener::is_init_trigger() {
2 if (init_at_startup() || is_initialized()) {
3 return false; // initialized at startup or already initialized
4 }
5 char path[PATH_MAX + 1];
6 int ret;
7 struct stat st;
8
9 snprintf(path, PATH_MAX + 1, "%s/.attach_pid%d",
10 os::get_temp_directory(), os::current_process_id());
11 RESTARTABLE(::stat(path, &st), ret);
12 if (ret == 0) {
13 // simple check to avoid starting the attach mechanism when
14 // a bogus user creates the file
15 if (st.st_uid == geteuid()) {
16 init();
17 return true;
18 }
19 }
20 return false;
21}
在收到信号之后,如果进程禁止被 Agent Attach (即 DisableAttachMechanism == true)或者 init_trigger 失败(比如 uid 检查不一致),则不进入 if 中,往下执行。如果配置了 PrintClassHistogram 则就会进行 Heap Inspection 操作,然后代码中注释就写了 force full GC before heap inspection。
使用 java -XX:+DisableAttachMechanism -XX:+PrintClassHistogram -verbose:gc -jar x.jar 即可轻松复现,用户提供的 gc 日志中的 Java cmdline 参数也印证了这一点。我们需要尽可能的提前发现 Attach 失败的因素,避免去 Attach 这些 Java 进程。
Java 内存中存在大量内存马相关的类无法被 GC
在初始版本的 Agent 中,其入口并非直接为业务逻辑,而是一个叫 Bootstrap 的类,作用是反射加载 Jar 中的业务逻辑入口类并执行。
这是因为 Java 存在字节码缓存机制,相同的 ClassLoader 加相同的包名、类名只会加载一次, Agent 更新之后,其包名和类名如果没有发生变化,那执行的也还是老的字节码。
为了解决这个问题,老版本 Agent 的做法是最小化不变的部分,将入口改为一个自定义的 ClassLoader,每次实例化一个新的去加载剩余的字节码,这样虽然包名和类名还不变,但是 ClassLoader 是新的了,就不会被缓存了。
下面是一个出现了重复的内存马相关的类的日志信息,可以发现除了 com.chaitin.bootstrap.Bootstrap 以外,其他运行了两次内存马扫描,类都是两份。
1[arthas@13553]$ sc *chaitin*
2com.chaitin.agent.AgentMain
3com.chaitin.agent.AgentMain
4com.chaitin.agent.Checker
5com.chaitin.agent.Checker
6com.chaitin.bootstrap.AgentClassLoader
7com.chaitin.bootstrap.Bootstrap
8com.chaitin.transformer.ClassFileMetaInfo
9com.chaitin.transformer.ClassFileMetaInfo
10com.chaitin.transformer.DumpTransformer
11com.chaitin.transformer.DumpTransformer
12com.chaitin.util.ContextUtil
13com.chaitin.util.ContextUtil
14Affect(row-cnt:12) cost in 44 ms.
15
16[arthas@13553]$ sc com.chaitin.bootstrap.Bootstrap -d
17 class-info com.chaitin.bootstrap.Bootstrap
18 code-source /Users/admin/workspace/endoscope_old/target/bootstrap.jar
19 name com.chaitin.bootstrap.Bootstrap
20 isInterface false
21 isAnnotation false
22 isEnum false
23 isAnonymousClass false
24 isArray false
25 isLocalClass false
26 isMemberClass false
27 isPrimitive false
28 isSynthetic false
29 simple-name Bootstrap
30 modifier public
31 annotation
32 interfaces
33 super-class +-java.lang.Object
34 class-loader +-jdk.internal.loader.ClassLoaders$AppClassLoader@55054057
35 +-jdk.internal.loader.ClassLoaders$PlatformClassLoader@3dc67816
36 classLoaderHash 55054057
37
38Affect(row-cnt:1) cost in 11 ms.
这样的一个问题是每次运行,Java 进程中的内存马的类就会多一份,可能会给客户造成一些困扰 (或者容易在有其他问题的时候甩锅到内存马检测,怀疑你们的东西造成了内存问题,但是实际内存占用应该不会太大,即使一个小时扫一次内存马)。
当然这部分的 Java 类并不是真的无法 GC,而是其与普通的变量数据比,Java 类的 GC 的条件要苛刻一些,要等着 Java 自己 GC 不知道要什么时间了,但是强制触发 Full GC 是可以回收的。
1[arthas@13553]$ vmtool --action forceGc
2
3[arthas@13553]$ sc *chaitin*
4com.chaitin.bootstrap.AgentClassLoader
5com.chaitin.bootstrap.Bootstrap
6Affect(row-cnt:2) cost in 8 ms.
目标 Java 进程如果配置了 -XX:+PrintGCDetails 也会输出
1GC(6) Pause Full (JvmtiEnv ForceGarbageCollection) 29M->27M(54M) 27.620ms
这里在线上肯定不能采用这种办法,于是我们采用了避免缓存的第二种办法,即每次发布都更换包名,这个在 gradle 中也是非常简单的配置,shadowId 配置为发布的版本号或者日期即可。
1relocate 'com.cloudwalker.webshell', 'com.cloudwalker.webshell.' + shadowID
2
3manifest {
4 attributes(
5 'Agent-Class': 'com.cloudwalker.webshell.' + shadowID + '.agent.Agent',
6 'Premain-Class': 'com.cloudwalker.webshell.' + shadowID + '.agent.Agent',
7 )
8 if (!agentOnly) {
9 attributes(
10 'Main-Class': 'com.cloudwalker.webshell.' + shadowID + '.attach.Attach'
11 )
12 }
13}
Jit code cache 刷新导致业务性能下降
Jvm 会把一些热点代码编译并存入 CodeCache 中以此来提高程序运行的性能,当retransformClasses 之后,不管有没有修改字节码,会刷新和此类有关系的 CodeCache,直接的表现就是 C2 Compiler 线程 CPU 使用升高,业务的性能下降。
(此处本来应该有一张监控的截图,但是上面有水印,就暂时不放了。图上内容就是 code_cache 利用率突然降低、GC 耗时突然升高)
Jvm crash 在 zip 处理相关的 native 代码中
其实这是一个老问题了,和内存马检测也没关系,但是我们遇到过客户出现了这个问题,而且怀疑和内存马检测有关,所以这里简单的说一下。
问题的核心是 Java 某些老版本会将 jar 文件进行 mmap,方便 zip 的处理,如果这个文件在使用过程中被修改了(比如上线操作等),那就可能会出现进程的崩溃。其典型的栈信息是
1Stack: [0x00007f607850e000,0x00007f607860f000], sp=0x00007f607860c370, free space=1016k
2Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code)
3C [libzip.so+0x5058] ZIP_GetEntry+0x78
4C [libzip.so+0x3eed] Java_java_util_zip_ZipFile_getEntry+0xad
5J java.util.zip.ZipFile.getEntry(J[BZ)J
如果还有 coredump 文件存在的话,可以加载到 gdb 中去看下读取哪个 Jar 出错的。
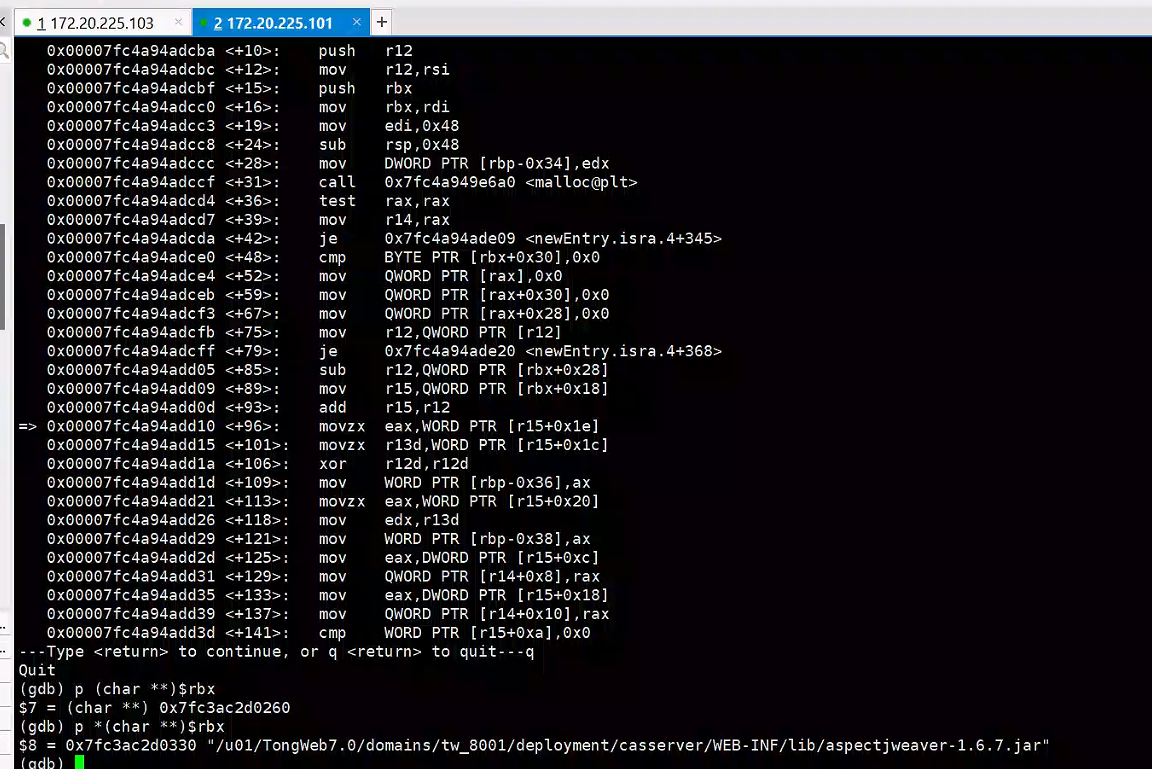
Java 新版本中已经将这部分逻辑切换到 Java 代码实现了,所以不再有这种问题,参考 https://bugs.openjdk.org/browse/JDK-8142508 。
其他 Jvm bug 系列
transform 一个字节码在 Jvm 内部逻辑是比较复杂的,首先需要从 Jvm 内部的 class 对象中拼接构建出来字节码 buffer,然后交给 transformer,如果需要替换对应的类,那还得确定那个类是否正在运行,如果正在运行的话,就需要维护一个历史的版本,稍后再去替换。
在客户现场遇见了几次 crash 的情况,原因各不相同
- https://bugs.openjdk.org/browse/JDK-8156137 一个类如果有多个版本,就需要清理不用的版本,老版本清理的时候存在遗漏,被后续的 gc 清理的时候会问题。
- https://bugs.openjdk.org/browse/JDK-8178870 一个类如果 transform 出来的字节码是非法的,那需要将其加入清理队列,然后出现了类似上面 double free。
jsr292 中新定义的一种 VM 匿名类(注意,非 Java 语法层面的匿名类),其常量池和传统 Java 类不一样,只要调用 retransform 函数,Jvm 就会稳定崩溃,这种不属于传统意义上的 Java 类,无法 transform。参考 https://www.zhihu.com/question/51132462 ,在 https://github.com/AdoptOpenJDK/openjdk-jdk8u/blob/master/hotspot/test/compiler/jsr292/VMAnonymousClasses.java 存放有 demo 代码。
不过这个问题还算好解决,因为其类名中含有 /,直接排除即可。
这些 Jvm 崩溃的问题严重影响 agent 和客户生产环境的稳定性,有些问题也没有在 Java 层面规避的方法,只能进行功能上的降级。目前我们实现了多种降级模式,包括
- 永远不使用 transform 功能
- 在部分确定有 bug 的版本上不使用 transform 功能
- 不降级处理
在实际场景中,有些 Java 类的只基于名字规则就可以判定了,不需要字节码,这样的话,即使不使用 transformer,我们也使用它的名字保存一个假的类字节码来作为样本进行检测。

提交中...